Statistikk: Eksempel på analyse (2)
Under vises et datasett som kan illustrere noen litt mer komplekse analyser. Datasettet består av tre sett av spørsmål innhentet fra en gruppe studenter. Disse studentene har gjennomgått et kurs, og vi er interessert i hvordan studenten selv, dennes kollegaer og dennes overordnede vurderer utbyttet av kurset. Vi har innhentet tre forskjelige mål, som fokuserer på KJENNSKAP (variabel 10), KOMPETANSE (variabel 16) og EFFEKT (sameskåre ikke vist på figuren). Spørsmålene hadde svaralternativer fra 1 (maks positiv skåre) til 5 (minimumskåre).
- De tre variablene er beregnet fra svar på enkeltspørsmål. KJENNSKAP er gjennomsnittet av variablene 4-9, KOMPETANSE er gjennomsnittet av variablene 11-15, EFFEKT er gjennomsnittet av variablene 17-21
- Variabel 1 angir målpersonens identitet. Merk at hver målperson har tre skårer (se neste punkt)
- Variabel 3 angir hvem som har gitt skårene. Det fremgår her at vi har skårer fra tre informanter, STUDENT, KOLLEGA, OVERORDNET
- Variabel angir LOKALITET, nærmere bestemt hvor i landet informantene er lokalisert
Det er relativt mye informasjon som ligger i dette datasettet. Hvordan kan disse dataene analyseres?
 Her er noen interessante analyser:
Her er noen interessante analyser:
- Et første spørsmål vi kan stille, er om det er konsistens innen hvert hovedmål. Mer spesifikt, hvor konsistente er enkeltmålene som inngår i variabelen KJENNSKAP (dva. variablene 4-9), og hvor konsistente er målene som inngår i variabelen KOMPETANSE (variablene 11-15)? Det sier seg selv at mye variasjon innad i hvert av disse målene ikke er bra. Slik konsistens sjekkes med Chronbach's alfa; se her for et eksempel. I dette tilfellet er Chronbach's alfa for enkeltmålene som inngår i KJENNSKAP 0,75, hvilket er så som så. Verdien bør være helst være i størrelsesorden 0,80-0,90
- En vanlig måte å angripe en analyse på, er å lage en krysstabell. I dette tilfellet er vi kanskje interessert i å fokusere på hvordan skårer på de tre variablene henger sammen med hvem det er som skårer (informant). Tabellen under gir et svar:
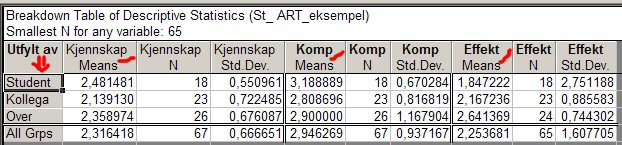
Vi ser at det er en viss forskjell i gjennomsnittene over de tre informantene på hver variabel. Er dette tilfeldige forskjeller, eller reflekterer de systematiske forskjeller i vurdering?
- Et interessant spørsmål vi derfor kan stille, er om det er konsistens mellom informantene: Gir STUDENT, KOLLEGA og OVERORDNET like vurderinger på de variablene vi har målt? For å gjennomføre en slik analyse, bruker vi en statistisk prosedyre som kan undersøke forskjeller mellom flere gruppegjennomsnitt, nemlig ANOVA. Siden vi i denne situasjonen også har tre variabler som måles for hevr informant (KOMPETANSE, KJENNSKAP, EFFEKT), må vi bruke en variant av ANOVA som tillater å inkludere repeterte målinger (dvs. flere målingen per deltaker). Analysen viser at det ikke er noen signifikant effekt av en variabelen vi her er interessert i, nemlig INFORMANT (variabelen Utfylt av). Se figuren under.
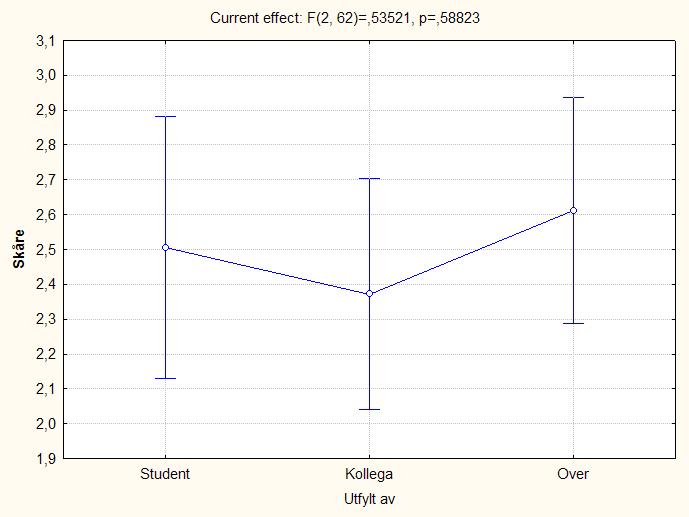
- I figuren over slo vi sammen de ulike målene vi egentlig er interessert i (KJENNSKAP, KOMPETANSE, EFFEKT). Kanskje er det en forskjell melom disse? Vel, det kan vi enkelt undersøke. Grafen under viser at vurderingen av KOMPETANSE ligger noe høyere enn de andre; det er en signifikant forskjell mellom de tre variablene (se figuren under). Merk også at det er større spredning skårene som inngår i variabelen EFFEKT enn i de andre to variablene.
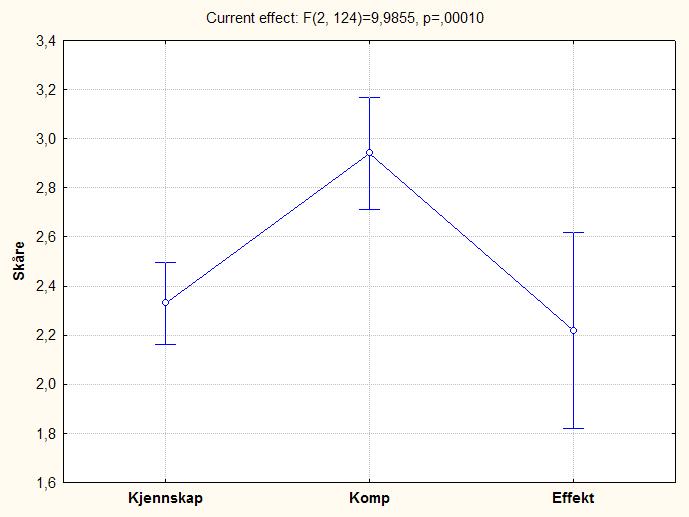
- Begge disse figurene belyser konkrete spørsmål vi stiller til data. Men hvordan ser "egentlig" dataene ut? Under ses en grafisk fremstilling av hele datasettet.

 Tilbake Tilbake
| |
|
|
